This is the second of a two-part post in which I describe four broad research trends that I observed at ACL 2017. In Part One I explored the shifting assumptions we make about language, both at the sentence and the word level, and how these shifts are prompting both a comeback of linguistic structure and a re-evaluation of word embeddings.
In this part, I will discuss two more very inter-related themes: interpretability and attention.
Throughout, green links are ordinary hyperlinks, while blue links lead to papers, and offer bibliographic information when you hover over them (not supported on mobile).
Trend 3: Interpretability
I’ve been thinking about interpretability a lot recently, and I’m not alone – among deep learning practitioners, the dreaded “black box” quality of neural networks makes them notoriously hard to control, hard to debug and thus hard to develop. From a non-researcher perspective however, there is an even more important reason to desire interpretability: trust.

One of many unsettling images used to depict AI in the media. By Keith Rankin.
The public, the media and some researchers are expressing increased anxiety about whether AI can be trusted if it cannot be understood. While some of these anxieties are ill-founded (see the “Facebook chatbots invent their own language” story), others are very real. For example, if AI systems absorb unwanted biases present in their training data, but we are unable to check the system for those biases, then we have a recipe for disaster. Second, as AI systems are imperfect and sometimes fail, then we must be able to check how they make their decisions – especially for more complex tasks. Third, even if AI systems operate perfectly, humans may always need the reassurance of explanation.
Even among researchers, “interpretability” can have many possible definitions – for an exploration of those definitions I highly recommend Zachary Lipton’s essay The Mythos of Model Interpretability. In particular, Lipton identifies two broad approaches to interpretability: post-hoc explanations and transparency. Post-hoc explanations take a learned model and draw some kind of useful insights from it; typically these insights provide only a partial or indirect explanation of how the model works. Transparency asks more directly “how does the model work?” and seeks to provide some way to understand the core mechanisms of the model itself. I think this is a useful distinction, so I’ll use it to explore the following ACL work.
Post-hoc explainability
At ACL, I saw many papers presenting a variety of creative methods to gain post-hoc insights into neural systems.
Visualization is probably the most common type of post-hoc interpretability, with particular types of visualizations – such as saliency maps and 2D projections of word embeddings – becoming standard. These visualizations are certainly useful (and I’m always grateful to see them in a paper), but they can be misleading if read incorrectly. In Visualizing and Understanding Neural Machine Translation, Ding et al. compute relevance scores that quantify how much a particular neuron or hidden state contributes to another neuron or hidden state. At first glance, the visualizations provided in the paper (which essentially give an importance score to each hidden state and its associated token) look very similar to the visualizations commonly produced from the attention distribution. However, the method of computation is very different. The relevance scores are a direct measure of how much one neuron affects a downstream neuron, calculated post-hoc on the trained model. By contrast the attention distribution is learned and computed by the network itself; it is an intermediate representation that affects the rest of the computation in complex ways. Though attention often plays the role of word alignment in NMT, Koehn and Knowles note that it learns to play other, harder-to-understand roles too; thus it is not always as understandable as we might hope. Ding et al.’s relevance scores provide a useful alternative way to measure word-level relevance in sequence-to-sequence models.
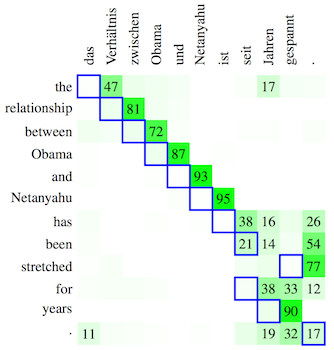
Koehn and Knowles show attention is sometimes off-by-one from word alignment. How should we interpret this behavior?
Transfer learning is another popular post-hoc analysis technique, in which the representations learned for task A (typically a high-level task) are applied to task B (typically a lower-level task). The degree of success at task B indicates how much the task A model has learned about task B. At ACL 2017, researchers asked what NMT models know about morphology, what Language Models know about NER and chunking, and what speech+vision representations know about various semantic tasks. These studies, which are often carefully repeated with different layers and various configurations of the task A model, can yield useful and unexpected insights that guide the development of better models for task A. For example, in What do Neural Machine Translation Models Learn about Morphology? Belinkov et al. find that while attention increases the quality of morphological information in the encoder representations, it decreases the quality for the decoder representations. I was surprised to read about this unintended side-effect of attention, and overall I really like how the paper thoughtfully and thoroughly addresses its research questions.
Though transfer learning and attention-like visualizations can tell you “how much”, they do not tell you “what” or “why”. To answer the latter, some researchers directly study the geometry of the representation spaces themselves. In Emergent Predication Structure in Hidden State Vectors of Neural Readers, Wang et al. provide evidence that in RNN-based reading comprehension models, the hidden vector space can be decomposed into two orthogonal subspaces: one containing representations of entities, and the other containing representations of statements (or predicates) about those entities. Though it is not a focus of the paper, I wonder whether these component parts of the hidden state could be further interpreted. In Parameter Free Hierarchical Graph-Based Clustering for Analyzing Continuous Word Embeddings, Trost and Klakow perform clustering on word embeddings, then cluster those clusters, and so on to obtain a hierarchical tree-like structure. Judging by the examples provided in the paper, the hierarchy could provide a more human-readable way to explore the neighborhood structure of word embeddings.
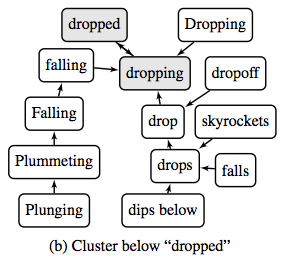
Trost and Klakow
Another approach to direct post-hoc interpretation is to treat interpretation itself as a translation task. In Translating Neuralese, Andreas et al. take the vector messages (“neuralese”) passed between two machines trained to perform a collaborative task, and translate them into natural language utterances. To overcome the absence of neuralese-to-English parallel data, Andreas et al. consider a pair of messages equivalent if they are used in similar scenarios by human and machine agents. The authors raise important questions about whether these translations can be trusted. What happens if the neuralese messages encode concepts that are impossible to capture in English? If humans and machines have different biases about what they choose to communicate, how can we be sure that crowdsourced training data contains English examples that correspond to the neuralese? In any case, this was one of my favorite papers of the conference, and I’m excited to see where this research goes next.
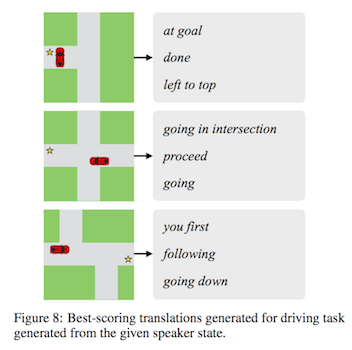
Andreas et al.
Transparency
Despite all the work gleaning post-hoc insight from uninterpretable neural models, some researchers argue that (notwithstanding finding the odd sentiment neuron) staring into the neurons will only get us so far. True interpretability requires transparency – models that are constructed and trained to be interpretable in themselves.
Linguistically-structured representations are by definition more interpretable than unstructured ones – thus Trend 1 (structure is back) could also be viewed as a move towards more transparent neural models. However, a core challenge with these, and other attempts to create transparent neural models is the tension between discreteness and continuousness. Neural networks are powerful because they can learn arbitrary continuous representations, but humans find discrete information – like language itself – easier to understand.
We might be concerned that imposing discreteness constraints on our neural models diminishes their expressive power – that interpretability comes at the price of effectiveness. However, for some types of discreteness, like sparsity, the opposite can be true. For example, sparsity-inducing regularization is known to improve rather than impair neural models, and sparsified word embeddings can be more effective than the original dense ones. In Sparse Coding of Neural Word Embeddings for Multilingual Sequence Labeling, Gábor Berend demonstrates the effectiveness of sparse word embeddings for NER and POS-tagging, particularly in low-training-data settings. Though interpretability is not the focus of Berend’s paper, he kindly answered my questions on the subject and even wrote a follow-up blog post, which shows that some of the basis vectors in the sparse representation seem to correspond to human-understandable concepts. This is very cool, and raises the question: if we have high-performing word embeddings with interpretable dimensions, can we use them to build more complex neural systems that are also interpretable?
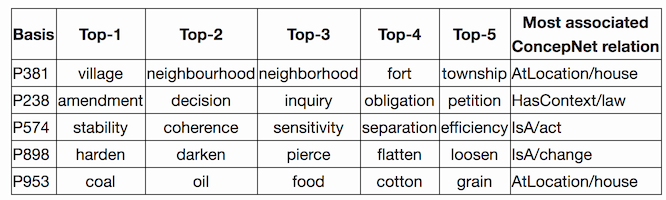
Gábor Berend
For AI systems that compute answers to complicated questions, transparency is especially important if humans are to trust the answers. These systems should ideally produce a proof or derivation of the answer – for a semantic parsing question answering system, this might be the semantic parse itself, or a relevant excerpt from the knowledge base. For a system that solves mathematical problems, the proof should be a step-by-step natural language derivation of the final answer. This is exactly what Ling et al. provide in Program Induction for Rationale Generation: Learning to Solve and Explain Algebraic Word Problems. Rather than directly and uninterpretably producing the final answer, their system jointly learns to generate the underlying sequence of mathematical transformations, and the natural language solution that explains it.
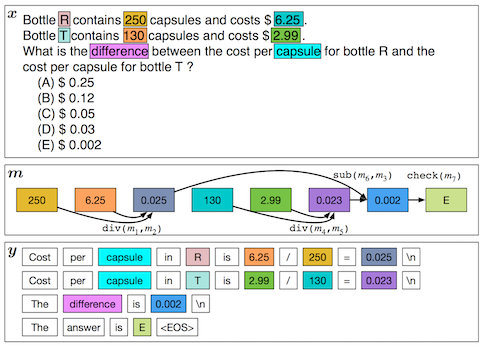
Ling et al.
Looking forward
I’m unsure which type of interpretability – post hoc explainability or transparency – is the right way forward. Post hoc techniques tend to give restricted explanations that, while fascinating, but are often cryptic themselves. I think that more flexible explanation techniques, like the translation-based approach, hold a lot of potential – though they raise tough new questions about trust. Transparency, on the other hand, is attractive because interpretability should really be a design choice, not an afterthought. Though we are far from building neural systems that are transparent end-to-end, efforts to make small parts of the system transparent are hugely useful – note, for example, how useful the attention mechanism has been as a sanity check and debugging tool for developing attentional systems. Which leads us to Trend 4…
Trend 4: Attention
Widely acknowledged as a game-changer for the sequence-to-sequence model, the attention mechanism is quickly becoming a favorite technique, and it’s easy to see why. It can be used to bypass bottlenecks in information flow, it enables a key-value lookup function that can’t be achieved with feed-forward layers, and it provides some much-needed interpretability. The attention mechanism had an increased presence at ACL this year, with fifteen occurrences of “attention” in paper titles (an increase from nine the previous year).
More attention everywhere
The attention mechanism is the most interpretable and therefore most manipulable part of the sequence-to-sequence framework. Accordingly, researchers are finding success by designing increasingly complex attention models that aim to solve particular task-specific problems. This “mini-industry of model extensions” (as described by Alexander Rush in his NMT workshop keynote) was thriving at ACL 2017.
Three papers presented models for Question Answering that, in addition to the usual question-to-document attention, add document-to-question attention. Of these models (attention-over-attention, cross-attention and gated-attention reader), the third also incorporates multi-hop attention, which allows the model to iteratively attend to different sections before coming to an answer. This seems like a core ability, and the appendix of the paper contains several examples that demonstrate both the necessity and the effectiveness of multi-hop reasoning.
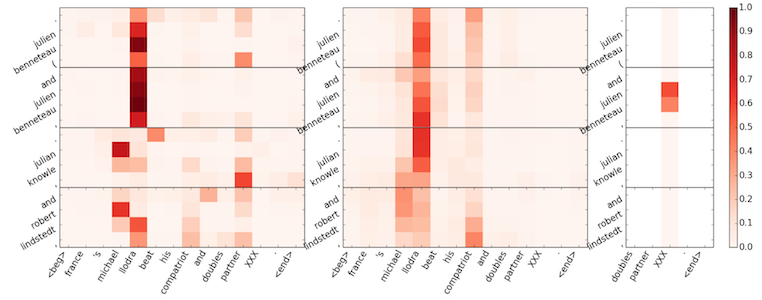
Over multiple iterations, attention settles on the correct answer. Dhingra et al.
Attention has also emerged as the standard way to weight and combine information from multiple, potentially multi-modal, sources. Libovicky et al. attend to both text and an image to translate a caption, Lin et al. attend to multi-lingual data to extract relations, and Kim et al. attend to the representations from an ensemble of domain experts to perform domain adaptation on a case-by-case basis. Attention is convenient in these cases because it offers a general way to obtain a fixed-size representation from an arbitrary number of sources.
Others find that applying attention at multiple granularities is useful for certain tasks. For example, grammatical error correction requires nested attention: word-level attention to detect word order errors, and character-level attention to detect spelling errors.
So is attention all you need?
The enthusiasm for increasingly complex, attentionattention mechanisms may seem to confirm recent bold claims that attention is all you need. However, at ACL I noticed several researchers deliver cautionary messages about the potential pitfalls or misapplications of attention.
For example, there are some scenarios in which attention doesn’t work as well as we might hope. Tan et al. argue that for abstractive document summarization, the attention distribution does not effectively model the saliency of source sentences. Instead, they find more success by using a pre-deep-learning extractive summarization algorithm (PageRank-based sentence ranking) to model saliency. This result serves as an important reminder that we should not throw away decades of accumulated NLP knowledge – though unfashionable, these techniques may provide the key to improving our neural systems.
Second, there may be some scenarios in which attention is redundant. Bollman et al. find that when they introduce an auxiliary task for multi-task learning, the addition of an attention mechanism becomes harmful rather than helpful. As explanation, they provide evidence that the auxiliary task enables the model to learn to focus attention, which makes the attention mechanism redundant. Though I don’t fully understand this interaction between attention and multi-task learning, we should take note of the phenomenon as it poses a potential pitfall for the development of future systems.
Lastly, there are some simpler tasks for which attention may be more than you need. Aharoni et al. argue that for morphological inflection generation, which typically requires focusing on just one character at a time, the standard “soft” attention is overkill – they find the simpler “hard” attention sufficient.
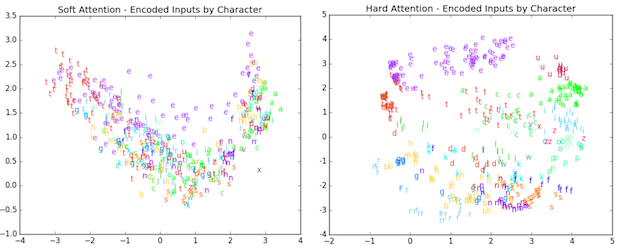
Hard attention produces more clearly-defined clusters than soft attention. Aharoni et al.
Looking forward
Although attention was originally conceived as a fix to the bottleneck problem in sequence-to-sequence NMT, it has turned out to be a much more fundamental and generally useful technique. By thinking about why attention is so popular, we might identify some of the current needs of the deep learning community – for example the need for interpretability, for long distance dependencies, and for dynamic structure. I hope that attention is just the first step towards achieving these things.
Conclusion
Though this is only the second ACL I’ve attended, I was really impressed by this year’s organizing committee, who did an amazing job of being transparent, listening to the community’s concerns, and proactively addressing them. This year’s conference featured an extensive open discussion of preprint servers and the submission process, as well as a strong emphasis on diversity, accessibility and ethics. In this era of very empirical-driven work, I was also glad to see multiple reminders that we should aspire to do good, hypothesis-driven science that is replicable and reproducible.
Just a few years after the deep learning tidal wave, the NLP community has reason to feel both excited and anxious – excited about where deep learning will lead next, and anxious about whether that’s the right direction. But I have confidence in this community to get the best out of both deep learning and NLP; to change with the times while retaining its collective wisdom. So, no need for hype nor fear. Deep learning is neither the ultimate solution nor the death of NLP.
Thanks to my advisor Chris Manning who read several drafts of this post, as well as the following people who gave me their opinions and/or answered my questions about their work: David Jurgens, Lucy Li, Gábor Berend, Yang Liu, Jiwei Tan.
What themes and trends did you observe at ACL 2017? Discuss in the comments.