This is a two-part post. Click here for Part Two.
Click here to read a shortened version of this post translated to Chinese.
Introduction
“NLP is booming”, declared Joakim Nivre at the presidential address of ACL 2017, which I attended in Vancouver earlier this month. As evidenced by the throngs of attendees, interest in NLP is at an all-time high – an increase that is chiefly due to the successes of the deep learning renaissance, which recently swept like a tidal wave over the field.
Beneath the optimism however, I noticed a tangible anxiety at ACL, as one field adjusts to its rapid transformation by another. Researchers asked whether there is anything of the old NLP left – or was it all swept away by the tidal wave? Are neural networks the only technique we need any more? How do we do good science now that experiments are so empirical, papers are immediately on arXiv, and access to GPUs can determine success?

Mirella Lapata expresses the community's concerns in her keynote
Though these difficult questions were at the forefront of the conference (the presidential address even alluded to a recent high-profile debate on the subject), the overall mood was positive nonetheless. At ACL 2017, the NLP community continued to enthusiastically embrace deep learning, though with a healthy skepticism. As researchers are starting to reach a clearer view of what works and what doesn’t with current neural methods, there is a growing trend to consult older NLP wisdom to guide and improve those methods. In this post I take a look at what’s happening at this pivotal time for NLP research.
About this post
In this two-part post, I describe four broad research trends that I observed at the conference (and its co-located events) through papers, presentations and discussions. The content is guided entirely by my own research interests; accordingly it’s mostly focused on deep learning, sequence-to-sequence models, and adjacent topics. This first part will explore two inter-related themes: linguistic structure and word representations.
Green links are ordinary hyperlinks, while blue links lead to papers, and offer bibliographic information when you hover over them (not supported on mobile).
Disclaimer: This recap is by no means exhaustive, as I did not come close to reading every paper at ACL – consequently I’m sure there are many relevant papers that are not mentioned here. Secondly, I have done my best to accurately understand others’ work, but if I’ve misrepresented any piece of work, let me know. Thirdly, as a person who is fairly new to the field, I may lack a longer perspective on some of these trends. If you have a more historically-informed perspective, I’d be interested to hear it.
Trend 1: Linguistic Structure is Back
The recent deep learning renaissance has emphasized a simple uniform paradigm for NLP: language is just sequences of words. According to this logic, any further structure is unnecessary – simply train a RNN end-to-end and stochastic gradient descent will figure out the rest! While this approach has rapidly found enormous popularity and success (not least due to the convenience of requiring no feature engineering), its limitations are now becoming more apparent. At ACL 2017, several prominent researchers pushed back against the “language is just sequences” zeitgeist and presented reasons, both practical and principled, why NLP should re-embrace linguistic structure.
Reason 1: Reduce the search space
In her very entertaining keynote talk, Mirella Lapata questioned the hegemony of the RNN sequence-to-sequence framework, asking rhetorically whether its dominance means language is dead, and all linguistic features should be discarded. Instead she concluded that Structure Is Coming Back, and provided via example one reason to embrace its return: linguistic structure reduces the search space of possible outputs, making it easier to generate well-formed output.
For example, code generation involves mapping a natural language utterance such as “generate a list of the first 10 square numbers” to a corresponding code snippet, e.g. “[x**2 for x in range(10)]” in Python. This task has been attempted with the standard sequence-to-sequence method, which regards the code as simply a sequence of tokens, rather than its underlying tree structure. This makes the generation task an unconstrained search over the entire output space of all sequences of tokens – a search task that is both daunting and prone to generate ill-formed output (for example, the decoder may generate code with mismatched brackets). In their ACL papers, both Yin and Neubig and Rabinovich et al. take the structured prediction approach instead, and directly generate the underlying abstract syntax tree. This approach restricts the search space to well-formed trees only, eliminating ill-formed output and making the search problem more manageable.
Though linguistic structure has obvious benefits for tasks with highly-formalized output such as code generation and semantic parsing, it can also help reduce the search space for less obvious tasks, like cloze-style reading comprehension. By observing that the correct answer is almost always a constituent in the source document’s parse tree, Xie and Xing construct a system that explores only those nodes – they argue this is both easier and more effective than exploring all possible spans in the document.
Reason 2: Linguistic scaffolding

Noah Smith
In his keynote talk, Noah Smith argued against what he calls the “all-squash diet” – the use of linear transformations + squashing functions (a.k.a. neural networks) as the sole model for NLP. Instead he encouraged the NLP community to think about our models’ inductive biases – that is, the models’ underlying assumptions and how those assumptions affect what they learn.
In particular, Smith highlighted the power of multi-task learning as a way to incorporate a desirable inductive bias. It is well-known that jointly learning a linguistic scaffolding task (such as syntactic parsing) with the main task (such as machine translation) tends to boost the performance of the main task – most likely because the main task is enriched by the useful information contained in the low-level shared representations. ACL saw several papers successfully take this approach – in particular Eriguchi et al. and Wu et al. designed new hybrid decoders for NMT that use shift-reduce algorithms to simultaneously generate and parse the target sequence.
These joint NMT+parsing systems, which seem to outperform sequence-to-sequence systems, may also benefit from Reason 1 (reducing the search space). As has been noted, NMT performance is poor for long sentences, and (counter-intuitively) larger beam sizes can sometimes degrade performance further. If widening the search beam causes a drop in performance, this implies that our current methods have difficulty identifying the best output when there are more candidates to choose from. Jointly parsing the output may eliminate poor-quality outputs from the search beam, thus allowing beam search to choose between better-quality candidates.
Reason 3: Syntactic recency > sequential recency
Chris Dyer also argued for the importance of incorporating linguistic structure into deep learning in his CoNLL keynote Should Neural Network Architecture Reflect Linguistic Structure? Like Noah Smith, he drew attention to the inductive biases inherent in the sequential approach, arguing that RNNs have an inductive bias towards sequential recency, while syntax-guided hierarchical architectures (such as recursive NNs and RNNGs) have an inductive bias towards syntactic recency. Asserting that language is inherently hierarchical, Dyer concluded that syntactic recency is a preferable inductive bias to sequential recency.
At ACL, several papers noted the apparent inability of RNNs to capture long-range dependencies, and obtained improvements using recursive models instead. For example, in Improved Neural Machine Translation with a Syntax-Aware Encoder and Decoder, Chen et al. find that using a recursive encoder improves performance overall, and the improvement is greater for longer sentences. The latter may be evidence of the benefit of syntactic recency, which can capture long-term dependencies more easily than sequential recency.
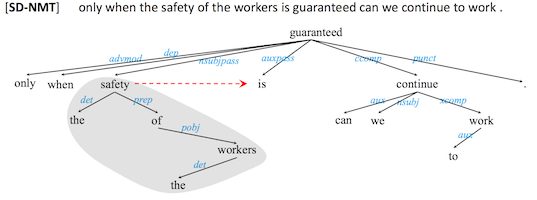
This example from Wu et al. shows the difference between syntactic recency (red dotted line) and sequential recency.
Looking forward
Though linguistic structure is making a comeback, some barriers remain. Multi-task learning is cumbersome to implement. Non-sequential architectures are harder to parallelize on GPUs (however new dynamic libraries provide easier and more efficient implementations). Supervised learning of structured prediction tasks can be hindered by a lack of parallel data. Fortunately, the resurgence of Reinforcement Learning is well-timed; at ACL 2017 both Liang et al. and Iyyer et al. use weak supervision to perform question answering via semantic parsing, without access to the parses themselves.
Despite these barriers, I think the NLP community will continue to (re-)embrace linguistic structure as its benefits become more apparent. While the “language is just sequences” paradigm argues that RNNs can compute anything, researchers are increasingly interested in how the inductive biases of the sequential model affect what they do compute. On this matter, it seems that a little linguistic structure can go a long way.
Trend 2: Reconsidering Word Embeddings
The number of papers with “word embedding” in the title fell from ten to four this year, perhaps in part due to a shift towards sub-word-level representations (more on that below). Nonetheless, word embeddings remain a standard technique, and the related papers at ACL this year were very interesting – perhaps precisely because word embeddings have passed through the “hype” stage and into the “thoughtful scrutiny” stage. These papers probed the boundaries of how word embeddings succeed and fail, what they do and don’t capture, and how to improve on their weaknesses.
Better understanding word embeddings
Perhaps the most famous and surprising (but often-exaggerated) success of word embeddings is their additive compositional structure, as evidenced by word analogies. The cryptically-titled Skip-Gram - Zipf + Uniform = Vector Additivity aims to explain this success. The authors prove that distributional word embeddings trained with the skip-gram model have additive structure under certain assumptions – most notably that the words are uniformly distributed (this is the meaning of “-Zipf +Uniform”). Though training corpora are not uniformly distributed, this result may go some way to explain the additivity of word embeddings.
Other papers investigated the limitations of the distributional assumption at the heart of word embeddings. Li and Gauthier ask Are distributional representations ready for the real world?, and find that while word embeddings capture certain conceptual features such as “is edible”, and “is a tool”, they do not tend to capture perceptual features such as “is chewy” and “is curved” – potentially because the latter are not easily inferred from distributional semantics alone. The paper joins a growing call for grounded learning, as evidenced by the founding of a new workshop on Language Grounding for Robotics.
Another, more glaring baked-in problem of word embeddings is that they do not account for polysemy, instead assigning exactly one vector per surface form. In one approach to this problem, Upadhyay et al. leverage multi-lingual parallel data to learn multi-sense word embeddings – for example, seeing the English word bank translated to both the French words banc and banque is evidence that bank is polysemous, and helps disentangle its two meanings. In Multimodal Word Distributions, Athiwaratkun and Wilson represent words not by single vectors, but by Gaussian probability distributions with multiple modes – thus capturing both uncertainty and polysemy. The paper has a very impressive Tensorboard demo: go to the “Embeddings” tab and search for a polysemous word like “zip”. You should find that the three modes are clustered with related words from the three different senses (zip code, clothes zip and zipped file).
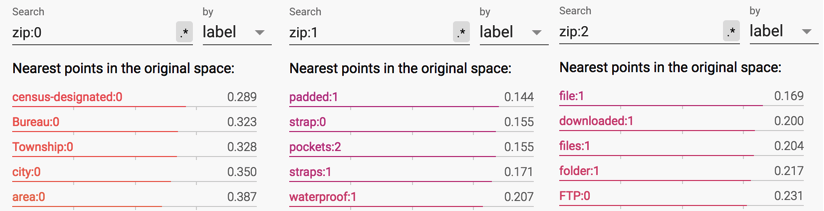
Athiwaratkun et al.
Going sub-word
Arguably the most urgent limitation of standard word embeddings is their blindness to morphological information, instead treating each surface form as a separate, anonymous unit. This can cause problems like an inability to recognize that two words (e.g. walker and walking) have the same lemma (walk) and are therefore highly related. This is the main reason for the recent shift away from word embeddings and towards sub-word representations, such as characters, character n-grams, and word pieces. These representations had a strong showing at ACL 2017, comparing favorably to word embeddings on both intrinsic tasks like word similarity and analogies as well as extrinsic tasks like Machine Translation, Language Modeling and dependency parsing. For logographic languages like Chinese/Japanese/Korean, the meaning of a character can be composed from the visual features of its component parts.
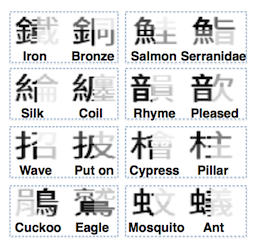
Visual compositionality of characters. Liu et al.
With these sub-word representations, and in particular the character-CNN emerging as a potential new standard, is morphology solved? At least two papers gave a resounding “no”. Vania and Lopez compared the language modeling performance of several sub-word compositional representations, and found that none of them perform as well as a model that has access to gold morphological annotations. This result held even when providing the raw input model with ten times the training data – suggesting that at best, our current language modeling methods require a very large amount of data to implicitly learn morphology, and at worst, no amount of training data can replace morphological understanding. In What do Neural Machine Translation Models Learn about Morphology?, Belinkov et al. show that while character-based NMT representations are better than word-based representations both for NMT and morphological tagging, they have far from perfect performance on the latter.
These results suggest that, if we want truly morphologically-aware word representations, we may need a more explicit model of morphology than just character composition. In their Morph-fitting paper, Vulić et al. fine-tune word embeddings by using some very simple morphological rules written by non-linguists (e.g., in English the prefix un- indicates an antonym). This results in substantial improvements, showing that even a modicum of linguistic knowledge can be very effective. Meanwhile, Cotterell and Schütze present a more comprehensive model of morphology, jointly learning a system that can both segment a word into its morphological components (e.g. questionably → question+able+ly) and compose the component representations back into the word representation. I think this is a very worthwhile approach, as any morphological understanding system must be able to compose and decompose meaning. Though the model performs well on the intrinsic evaluation tasks, I’d be interested to see how easily and how successfully it transfers to extrinsic tasks such as syntactic parsing or language modeling.
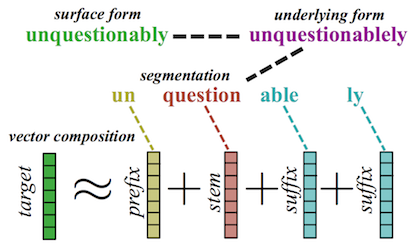
Cotterell and Schütze
Looking forward
Words are the very basis of language, so our assumptions matter when we choose how to model them.
Though distributional semantics has served us well so far, words are more than the contexts in which they appear. In the coming years I think we will see more grounded, visual and interactive language learning to complement distributional representations.
Like the “language is just sequences of words” assumption, “words are just anonymous tokens” seems to be on its way out. However, I expect the question of “words are just sequences of characters” vs. “morphological structure is important” will be a matter of future debate, both philosophical and practical.
Next time
If you’ve enjoyed this post, check out Part Two, in which I discuss interpretability and attention, and find that neither are as easy to define as we think they might be.